Definitive Technical SEO Checklist for Brands in 2026
SEO
Definitive Technical SEO Checklist for Brands in 2026

The team at Prosperity Media has worked on 100s of technical SEO site audits and SEO web migrations over the years. Mainly we help medium and large websites with organic visibility growth. We have decided to share some of our knowledge on Technical SEO.
This guide is designed to assist webmasters and in-house teams with technical SEO analysis and to share some common aspects we look into when completing analysis on websites. Some webmasters may think that Technical SEO is a one-off project. While it is true that you don’t usually need to perform a full technical SEO every month, it should be an important part of your overall digital strategy.
We recommend that you perform a full audit at least once a year. It is also advisable to complete regular technical SEO sweeps and crawls each month, these will provide number of recommendations on aspects that you can fix. You should also be monitoring Google Search Console and Bing Webmaster Tools on a weekly basis to ensure SEO performance is running at an optimal level.
What Tools Do You Need To Perform A Proper Technical SEO Site Audit?
To make the best use of our guide:
- You will need to have an existing website – if you’re responsible for making on-page changes then you will need administrative access to the backend.
- You will need a web crawler – we recommend Sitebulb or Screaming Frog SEO Spider Tool & Crawler (both apps provide either a 7-day free trial or a limited number of page crawls). This is all you will need for an initial audit to identify problems.
- SEMrush – powerful crawler to identify orphan pages.
- Ahrefs – powerful crawler to identify backlinks, anchor text, and keyword overlap.
- Sitemap Test – by SEO SiteCheckup.
- You will need access to your site’s Google Search Console.
- Chrome browser + User-Agent Switcher for Chrome.
- Hreflang.ninja – quickly check whether your rel-alternate-hreflang annotations on a page are correct.
- https://varvy.com/mobile/
- PageSpeed Insights – by Google.
- You will need a website speed test – we recommend GTmetrix – creating a user account will give you finer control of the tool (e.g., testing location, connection speed etc.), or Pingdom.
- Structured Data Tool – by Google.
- Mobile-Friendly Test – by Google.
- Copyscape – this is a free tool that searches for duplicate content across the Internet.
- Siteliner – find duplicate content within your own site.
Now that you have all the tools necessary to perform a technical SEO site audit, let’s get started shall we? We have broken this checklist down into important sections you can complete analysis on.
1. Can Crawlers Find All Important Pages?
The Internet is an ever-growing library with billions of books without a central filing system. Indexation helps search engines to quickly find relevant documents for a search query. It does this through the use of web crawlers.
A web crawler (or crawler for short) is software used to discover publicly available web pages. Search engines use crawlers to visit and store URLs. It does this by following links they may find on any given web page.
When a crawler such as Googlebot visits a site, it will request for a file called “robots.txt”. This file tells the crawler which files it can request, and which files or subfolders it is not permitted to crawl.
The job of a crawler is to go from link to link, and bring data about those web pages back to a search engine’s servers.
Because there is no central filing system of the World Wide Web, search engines index hundreds of billions of web pages so that it may retrieve relevant content for a search query . This indexation plays an integral part to how search engines display web pages.
Therefore, one of the first things things to check is whether or not web crawlers can ‘see’ your site structure. The easiest way for this to happen is via XML sitemaps.
1.1 CHECK FOR A XML SITEMAP
Think of a XML sitemap as a roadmap to your website. Search engines use XML sitemaps as a clue to identify what is important on your site.
Use this free Sitemap Test to verify that your website has a XML sitemap.
If your website does not have a XML sitemap, there are a number of tools to generate one.
1.2 HAS THE XML SITEMAP BEEN SUBMITTED TO SEARCH ENGINES?
A XML sitemap must be manually submitted to each search engine. In order to do so, you will need a webmaster account with each search engine. For example, you will need Google Search Console to submit a XML sitemap to Google, a Bing Webmaster account to submit to Bing and Yahoo!, a Baidu Webmaster account and Yandex webmaster account for Baidu and Yandex respectively.
Each webmaster account will have a XML sitemap testing tool.
To check whether a XML sitemap has been submitted to Google, log into Google Search Console and on the navigation panel on the left of your screen, go to Index > Sitemaps.
On the older version of Google Search Console, navigate to Crawl > Sitemaps.
If a sitemap has been submitted, Google Search Console will display the results on this page.
If no sitemap has been submitted, you can submit one on the same page.
1.3 DOES THE XML SITEMAP HAVE FEWER THAN 50,000 URLS?
If your XML sitemap has more than 50,000 URLs, web crawlers will not attempt to index your web page. This is because crawling and indexing web pages across the Internet takes up a lot of computation resources. For this reason, if your site has thousands of pages, Google recommends splitting your large sitemap into multiple smaller ones.
Google Search Console will notify you if there are errors with your submitted sitemap.
1.4 DOES THE XML SITEMAP CONTAIN URLS WE WANT INDEXED?
Submitting a XML sitemap to Google does not mean that Google will index web pages.
A search engine such as Google will only index a page if it meets two criterion: (a) it must have found and crawled it and, (b) if it determines the content quality to be worth indexing.
A slow and manual way to check whether a page has been indexed by a search engine is to enter the URL of your domain with “site:” before it (e.g., site:yourdomain.com).
Tools such as Screaming Frog and Sitebub generate reports on whether web pages in your site are indexable. Seeing a ‘non-indexable’ in the report accompanied with a 200 status is not a cause for immediate concern. There are valid reasons why certain URLs should be excluded from indexation. However, if a high value page is non-indexable, this should be rectified as soon as possible because the URL has no visibility in search result pages.
Common reasons for crawling errors usually come down to configurations in one or more of these: robots.txt, .htaccess, meta tags, broken sitemap, incorrect URL parameters, connectivity or DNS issues, inherited issues (penalty due to previous site’s bad practices).
1.5 ARE THERE INTERNAL LINKS POINTING TO THE PAGES YOU WANT INDEXED?
Internal links are ones that go from one page on a domain to a different page on the same domain. They are useful in spreading link equity around the website. Hence, we recommend internal linking to high value pages in order to encourage crawling and indexing of said URLs.
1.6 ARE INTERNAL LINKS NOFOLLOW OR DOFOLLOW?
Building upon spreading link equity internally, the rel=”nofollow” attribute prevents PageRank from flowing through the specified link. It is used to prevent a page from being indexed. Therefore, you do not want nofollow links on your website.
To find out whether you have nofollow links on your site, run a Sitebulb analysis. Once completed, go to Indexability > Nofollow.
1.7 DO ANY PAGES HAVE MORE THAN 150 INTERNAL LINKS?
Search engine bots have a crawl limit of 150 links per page. Whilst there is some flexibility in this crawl limit, we recommend clients to limit the number of internal links to 150 or risk losing the ability to have additional pages crawled by search engines.
1.8 DOES IT TAKE MORE THAN 4 CLICKS FOR IMPORTANT CONTENT FROM THE HOMEPAGE?
The further down a page is within a website’s hierarchy, the lower the visibility the page will have in SERPs. For large websites with many pages and subpages, this may result in a crawl depth issue. For this reason, high value content pages should be no further than three to four clicks away from the homepage to encourage search engine crawling and indexing.
1.9 DOES INTERNAL NAVIGATION BREAK WITH JS/CSS TURNED OFF?
In the past, Googlebot was unable to crawl and index content created using JavaScript. This caused many SEOs to disallow crawling of JS/CSS files in robots.txt. This changed when Google deprecated AJAX crawling in 2015. However, not all search engine crawlers are able to process JavaScript (.e.g, Bing struggle to render and index JavaScript).
Therefore, you should test important pages with JS and CSS turned off to check for crawling errors.
Why is this important?
While Google can crawl and index JavaScript, there are some limitations you need to know.
- All resources (images, JS, CSS) must be available in order to be crawled, rendered and indexed.
- All links need to have proper HTML anchor tags.
- The rendered page snapshot is taken at 5 seconds (so content must be loaded in 5 seconds or it will not be indexed).
1.10 CAN CRAWLERS SEE INTERNAL LINKS?
Simply put, if a crawler cannot see the links, it cannot index them.
Google can follow links only if they are in an <a> tag with an href attribute. Other formats will not be followed by Googlebot.
Examples of links that Google crawlers cannot follow:
- <a routerLink=”some/path”>
- <span href=”https://example.com”>
- <a onclick=”goto(‘https://example.com’)”>
To check that your page can be crawled, inspect each individual link in the rendered source code to verify that all links are in an <a> tag with a href attribute.
1.11 CHECK FOR REDIRECT LOOPS
Redirect loops differ from redirect chains. Both issues impact the usability and crawlability of your website.
Redirect chains make it difficult for search engines to crawl your site and this will have a direct impact on the number of pages that are indexed. Redirect chains will also result in slower page loading times which increases the risk of visitors clicking away. This to, is a small ranking factor.
Redirect loops result in an error. Upon finding a redirect loop, a crawler hits a dead-end and will cease trying to find further pages to index.
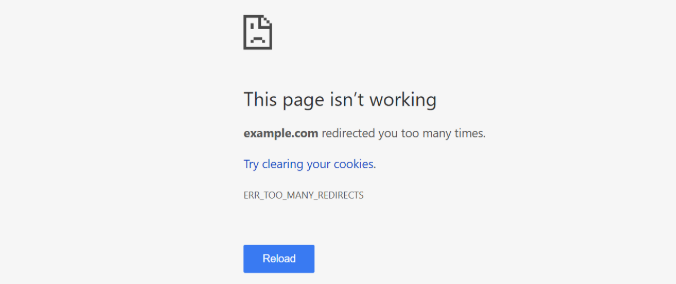
To illustrate a redirect loop, consider this: URL #1 > URL #2 > > URL #3 > URL #1. It first begins as a redirect chain then because it redirects the user or crawler back to the original link, a loop is established.
Should your website have a redirect loop, Sitebulb will identify them. Refer to their documentation on how to resolve a redirect chain and/or loop.
1.12 CHECK FOR ORPHANED PAGES
As the name implies, an orphaned page is a page without a parent. That is, there are no internal links pointing towards it. Orphaned pages often result from human error and because there are no references to the page, a search engine bot cannot crawl it and therefore, index it and display it within SERP.
There are specific situations where orphaned pages are preferred, for example, landing pages with unique offers that can only be access via PPC or email campaigns (these typically have a noindex meta tag applied). But if a high value page is orphaned as a result of a mistake, this needs to be resolved.
SEMrush has a dedicated tool for identifying orphaned pages. It is a premium tool used by SEOs.
2. Can Crawlers Access Important Pages?
In the previous section, we covered twelve things to check to ensure that crawlers can find important pages. By now, you should fully understand why you want spiders to be able to crawl all pages within your website.
In the second part of our technical SEO audit, your goal is to ensure that crawlers access all your money pages.
2.1 DOES THE CONTENT LACK A VALID AND UNIQUE URL?
AJAX is a set of development techniques that combine HTML, CSS, XML and JavaScript. Some sites serve dynamic content using AJAX often to prevent visitors needing to load a new page.
One of the benefits of AJAX is that it allows users to retrieve content without needing to refresh a page. In the past dynamic content was not visible to crawlers and in 2009, Google provided a technical workaround. But that all changed when Google announced that it was deprecating AJAX crawling scheme.
Using Fetch & Render tool found in Google Search Console, compare the results of the page and how Google views the page. If you have any rendering issues with the landing page you will be able to troubleshoot them using the tool.
2.2 DOES ACCESS TO THE CONTENT DEPEND ON USER ACTION?
Some pages require user action in order to display content.
User action in this situation may involve the clicking of a button, scrolling down the page for specified amount of time, or hovering over an object.
Since a web crawler cannot perform these tasks, it will not be able to crawl and index the content on the page.
Perform a manual check to see if a page’s content requires user action. If found, consider removing user action in order to display the content.
2.3 DOES ACCESS TO THE CONTENT REQUIRE COOKIES?
Browser cookies are tiny bits of text stored on your device by your web browser (e.g., Safari, Chrome, Firefox). Cookies contain information such as your session token, user preferences, and other data that helps a website keep track of one user from another. If your website has user accounts or a shopping cart, cookies are in play.
In terms of crawlers, Googlebot does so stateless. That is, without cookies.
Therefore, from a technical SEO perspective, you want to ensure that all your content is accessible without cookies.
Perform a manual check by loading the page with cookies disabled.
Similarly, you can crawl your site with Screaming Frog or Sitebulb with cookies turned off to identify if this issue exists.
2.4 IS THE CONTENT BEHIND A LOGIN SCREEN?
As search engine bots cannot access, crawl or index pages that require password login, pages behind a login screen will not be visible in SERPs.
Perform a site crawl without authentication to identify whether you have pages that cannot be accessed due to a login screen.
2.5 DOES CONTENT REQUIRE JAVASCRIPT TO LOAD AND DOES JAVASCRIPT PREVENT CRAWLERS FROM SEEING IMPORTANT CONTENT?
Googlebot uses a web rendering service that is based on Chrome 41. Tests have shown that Google can read JavaScript but we continue to have reservations on how well Googlebot and other crawlers handle JavaScript across millions of websites on a daily basis that use JavaScript.
For this reason, you should test important pages with JavaScript and CSS turned off to see if they load properly. One way to do this is to copy + paste the URL into Google Search Console Fetch & Render tool.
If content does not load properly, you will need to rectify the corresponding line(s) of code.
2.6 IS CONTENT INSIDE IFRAME?
It is common practice to use iframes to embed videos from YouTube, slideshows from SlideShare, maps from Google, or to use an iframe to embed a PDF so that visitors do not have to download it and then open it.
In the past, crawlers had difficulty crawling iframe content. These days, this is no longer the case.
Crawlers consider the content found in iframes to belong to another domain. Whilst this does not hurt rankings per se, iframes certainly do not help. This is why we recommend our clients to produce unique and valuable content.
To ensure that Google can see the content within an iframe, use Fetch & Render found inside Google Search Console.
2.7 IS CONTENT INSIDE FLASH OBJECT?
Adobe Flash files are not supported on many mobile devices. For example, Apple has never supported flash on any of its iOS devices). Similarly, Google announced in 2017 that it will remove Flash completely from Chrome toward the end of 2020. Even Microsoft, the ones responsible for Internet Explorer plans to end Flash support by the end of 2020.
Generally speaking, we do not recommend using Flash on your website. Instead, HTML5 Canvas combined with JavaScript and CSS3 can replace many complex Flash animations.
2.8 IS DIFFERENT CONTENT BEING SERVED TO DIFFERENT USER AGENTS?
Manually check pages using the Chrome add-on User-Agent Switcher for Chrome.
2.9 IS CONTENT BEHIND A URL FRAGMENT?
Google wants you to stop using URL fragments.
A fragment is an internal page reference, sometimes called a named anchor. Googlebot typically ignores fragments and as such, it is impossible for AJAX driven sites to get indexed due to their use of fragmented URLs.
How can you find which pages are behind a URL fragment?
Within Sitebulb, navigate to Filtered URL List > Internal HTML and then do a manual search for URLs containing the hashtag (#).
3. Can Crawlers Index All The Important Pages?
By this stage of this technical SEO audit, you will know how crawler-friendly your website is and how to fix crawlability issues if they were present.
In this section, we will address the indexability of your site.
3.1 WHAT URLS ARE ROBOTS.TXT BLOCKING?
The robots.txt file specifies which web-crawlers can or cannot access parts of a website. Some real-world applications of restricting crawler access include: preventing search engines from indexing certain images/PDFs, keeping internal search result pages from showing up on a public SERP, and to prevent your server from being overloaded by specifying a crawl delay.
A serious problem arises when you accidently disallow Googlebot from crawling your entire site.
Google Search Console has a robots.txt checker. Using robots.txt you can see if any restrictions have been applied.
3.2 DO ANY IMPORTANT PAGES HAVE NOINDEX META TAG?
A noindex meta tag can be included in a page’s HTML code to prevent a page from appearing in Google Search.
You will be able to spot it in a page’s source code by looking for <meta name=”robots” content=”noindex”>.
Therefore, to ensure that your site’s important pages are being crawled and indexed by search engines, check to see that there are no noindex occurrences.
3.3 ARE URLS RETURNING 200 STATUS CODE?
HTTP response status codes are issued by a server in response to a client’s request made to the server. Common status codes include 200 (OK), 301 (moved permanently), and 404 (not found).
Status code 200 is the standard response for successful HTTP requests. What this means is that the action requested by a client was received, understood and accepted. A status code 200 implies that a crawler will be able to find the page, crawl and render the content and subsequently, index the page so that it will appear in search result pages.
A site crawl using either Screaming Frog of Sitebulb will show you the response codes of all your pages.
Generally speaking:
- If you find the 302 HTTP status code, we recommend changing these to 301 redirects.
- Verify that pages with 404 status code are in fact unavailable (e.g., deleted page) then remove internal links to the page to prevent users hitting a 404 and then 301-redirect the URL to a relevant active page, or serve a 410 status code.
If you discover 500 (internal server error) and 503 (service unavailable) status codes, this indicates some form of server-side problem. Specific to site indexation, 5XX-type responses tell Googlebot to reduce the rate to crawl a site until the errors disappear. That’s right – this is bad news!
4. Does Duplicate Content Exist?
As much as 30% of the Internet is duplicate content. Google has openly stated that they do not penalise duplicate content. While technically not a penalty, in the world of SEO, duplicate content can impact search engine visibility/ranking.
For example, if Google deems a page as being duplicate in content, it may give it low to no visibility in SERP.
4.1 CHECK FOR POOR REDIRECT IMPLEMENTATION
Using Screaming Frog:
- Verify that both HTTP and HTTPS versions return a 200 status code.
- Verify that www and non-www versions return a 200 status code.
- Verify that URLs with and without trailing slash (/) return a 200 status code.
If any of the above steps produce a status other than 200, the existing redirect is not 301 and therefore should be changed to a 301-redirect. This can be done within your .htaccess file.
4.2 CHECK URL PARAMETERS
URL parameters as used by click tracking, session IDs, and analytics codes can cause duplicate content issues. To prevent bots from indexing unnecessary URL parameters, implement canonicalisation, noindex, or robots.txt to block them from crawling them.
Similar to checking for existing URL parameters, follow the steps outlined in 2.9.
4.3 ARE THERE THIN AND/OR DUPLICATE PAGES?
Do multiple URLs return the same or similar content?
Secondly, does your site have many pages with less than 300 words? If so, what value do these pages provide to visitors?
Use Sitebulb > Duplicate Content.

5. Can Crawlers understand the relationship between different pages?
5.1 HREFLANG ISSUES
In 2011, Google introduced the hreflang attribute to help website to increase their site’s visibility to users in multiple countries. In a 2017 study, over 100,000 websites had hreflang issues.
Here are 5 hreflang issues to look out for:
- Are hreflang meta tags used to indicate localised versions of the content?
- Does each page have a self-referential hreflang tag?
- Has hreflang=”x” been used to indicate the default version?
- Are there conflicts between hreflang and canonical signals?
- Does HTML language and region codes match page content?
Use hreflang.ninja to check whether rel-alternate-hreflang annotations have been implemented properly.
Perform a SEMrush site audit to check for hreflang implementation issues.
5.2 PAGINATION ISSUES
Paginated pages are a group of pages that follow each other in a sequence that are internally linked together.
Things to check for specifically:
- Do sequential pages have rel=”next” and rel=”prev” tags in the page header?
- Do navigation links have rel=”next” and rel=”prev?
- Do pages in a series have a self-referential canonical tag? Or a canonical points to a ‘View All’ page?
5.3 CANONICALISATION ISSUES
If you do not explicitly tell Google which URL is canonical, Google will make the choice for you.
Google understands that there are valid reasons why a site may have different URLs that point to the same page, or have duplicate or very similar pages at different URLs.
Check for the following canonicalisation errors using Sitebulb:
- Are canonical tags in use?
- Do canonical URLs return 200 status code?
- Do canonical declarations use absolute URLs?
- Are there any conflicting canonical declarations?
- Has HTTPS been canonicalised to HTTP?
- Do canonical loops exist?
5.4 MOBILE-SPECIFIC PAGE ISSUES
For sites that do not have a responsive design but rely on serving a separate mobile and desktop version, Google sees this as a duplicate versions of the same page. For example – www.yoursite.com is served to desktop users while m.yoursite.com is served for mobile users.
To help search engines understand separate mobile URLs, we recommend doing the following annotations:
- add a special link rel=”alternate” tag to the corresponding mobile URL (i.e. m.yoursite.com) on the desktop page (this helps crawlers discover the location of mobile pages);
- add rel=”canonical” tag on the mobile page pointing to the corresponding desktop URL (i.e. www.yoursite.com).
Therefore, when it comes to separate URLs for mobile and desktop users, check:
- Do mobile URL have canonical links to the desktop URL?
- Do mobile URLs resolve for different user agents?
- Have redirections been implemented via HTTP and JavaScript redirects?
For detailed instructions on how to implement, refer to Google’s support documentation on separate URLs.
Moving On From Crawling And Indexing
Beyond optimising your site for search engine crawling and indexing, we’ve put together a few more things you should check as part of your annual technical SEO audit. Specifically, this section relates to ranking factors and the common issues that can prevent your money page gaining SERP visibility it deserves.
1. KEYWORD CANNIBALISATION
Chances are that if your website has been around for a few years, you’ll probably have a few pages that target the same keyword(s). This in itself isn’t a problem as many pages rank for multiple keywords. According to a study by Ahrefs, the average page ranking in the first position also ranked for one thousand other relevant keywords.
Use SEMrush or Ahrefs to identify your site’s organic keywords and export them into a spreadsheet. Then filter the results alphabetically to see where keyword overlaps exist across your site.
2. ON-PAGE OPTIMISATION
Some basic on-page SEO to check for:
- Does each page have a unique and relevant title tag?
- Does each page have a unique and relevant meta description?
- Do images found on money pages marked with appropriate alt text?
- Is important content/information hidden in tabs/accordions?
- Do money pages have helpful content (text + images) for the targeted keyword(s)?
Use Sitebulb or Screaming Frog to help you identify the existence of duplicate title tags and meta descriptions.
3. IS YOUR SITE’S CONTENT UNIQUE?
Particularly for e-commerce sites where product descriptions and images are provided by the manufacturer, this type of duplicate content can impact SERP visibility. This is because search engines want to serve the most relevant pages to searchers and as a result they will rarely show multiple versions of the same content.
We always recommend our clients to write their own content, including production descriptions to avoid falling trap of duplicate content issues.
Use Copyscape to search for copies of your page across the Internet. If you do find another site has copied your content in violation of copyright law, you may request Google to remove the infringing page(s) from their search results by filling out a DMCA request.
Use Siteliner to search for copies of your page within your own site.
4. USER-FRIENDLINESS
Remember how we debunked one of the common SEO goals earlier?
The discipline of search engine optimisation is not trying to game a system but rather, to improve the search engine user’s experience in finding a solution to their problem.
Therefore, at the most basic level, check for the following:
- Are pages mobile-friendly?
- Are pages loading in less than 5 seconds?
- Are pages served via HTTPS?
- Are there excessive ads that push content below the fold?
- Are there intrusive pop-ups?
This is because a new visitor to your site will probably be impatient; a resource page that takes more than 5 seconds to load will result in the user bouncing. Similarly, if the intended formation is hidden behind excessive ads and pop-ups, the user will bounce away. As tempting it may be to display a full-screen call-to-action pop-up to a new visitor, this is a prime example of poor user-friendliness that Google discourages.
Use GTmetrix, Pingdom and PageSpeed Insights to determine what is causing slow page loads.
Images are the number one cause for delayed page loads. Make sure that you are serving correctly scaled images that have been compressed.
5. STRUCTURED MARKUP
According to Google, 40% of searches, especially local searches include schema data, however, more than 95% of local businesses do not have schema on their site or it is implemented incorrectly.
When done correctly, structured markup helps search engines to understand the meaning behind each page – whether it be an informational article or product page. The better a search engine understands your content, the more likely it will give it preferential SERP visibility.
To prove how Google preference for structured data, they have a dedicated case studies page.
Use Google’s Structured Data Testing Tool to identify existing errors and consider hiring a schema specialist to ensure that your pages have been optimised correctly. Abuse of structured markup can lead to manual penalty.
Learn more about Technical SEO with a recent presentation by Prosperity Media Technical SEO Manager –
Closing Remarks
With new found technical SEO knowledge you should have a selection of key issues you can fix on your website. The main thing with SEO is you constantly need to be making changes and staying up to date with industry news. New developments, tools and markups come out regularly so it’s important to keep up to date with them and test out everything where possible.
Depending on how large your business is, it might take several months to have developers implement technical SEO changes. If you work with a smaller businesses and you have direct access to a developer, you should be able to implement these changes quicker. It’s important to push the benefits of technical SEO to the wider organisation and implementing technical SEO changes at scale can have a highly positive effect on organic traffic.
If you need assistance with Technical SEO or any other area of SEO do not hesitate to get in content with the team at Prosperity Media.